Machine learning is part art and part science. When you look at machine learning algorithms, there is no one solution or one approach that fits all. There are several factors that can affect your decision to choose a machine learning algorithm.
Some problems are very specific and require a unique approach. E.g. if you look at a recommender system, it’s a very common type of machine learning algorithm and it solves a very specific kind of problem. While some other problems are very open and need a trial & error approach. Supervised learning, classification, and regression, etc. are very open. They could be used in anomaly detection, or they could be used to build more general sorts of predictive models.
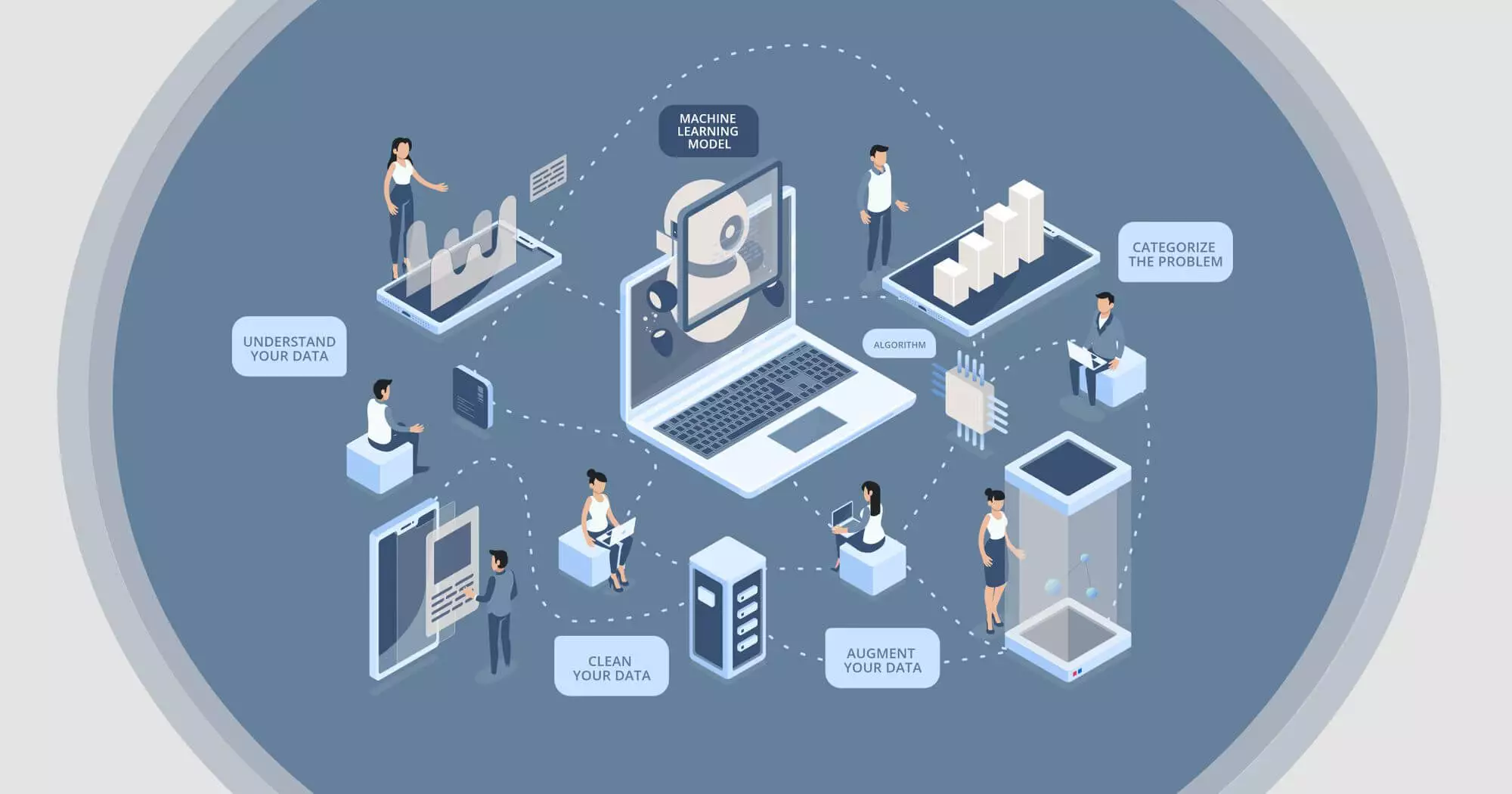
Understand Your Data
The type and kind of data we have to play a key role in deciding which algorithm to use. Some algorithms can work with smaller sample sets while others require tons and tons of samples. Certain algorithms work with certain types of data. So first Know your data.
Look at Summary statistics and visualizations
Percentiles can help identify the range for most of the data
Averages and medians can describe the central tendency
Correlations can indicate strong relationships
Visualize the data
Box plots can identify outliers
Density plots and histograms show the spread of data
Scatter plots can describe bivariate relationships
Clean your data
Deal with a missing value. Missing data affects some models more than others. Even for models that handle missing data, they can be sensitive to it (missing data for certain variables can result in poor predictions).
Choose what to do with outliers:
Outliers can be very common in multidimensional data.
Some models are less sensitive to outliers than others. Usually, tree models are less sensitive to the presence of outliers. However, regression models, or any model that tries to use equations, could definitely be affected by outliers.
Outliers can be the result of bad data collection, or they can be legitimate extreme values.
Augment your data
Feature engineering is the process of going from raw data to data that is ready for modeling. It can serve multiple purposes:
Make the models easier to interpret (e.g. binning)
Capture more complex relationships (e.g. NNs)
Reduce data redundancy and dimensionality (e.g. PCA)
Re-scale variables (e.g. standardizing or normalizing)
Different models may have different feature engineering requirements. Some have built-in feature engineering.
Categorize the problem
This is a two-step process.
Categorize by input. If you have labelled data, it’s a supervised learning problem. If you have unlabelled data and want to find structure, it’s an unsupervised learning problem. If you want to optimize an objective function by interacting with an environment, it’s a reinforcement learning problem.
Categorize by output. If the output of your model is a number, it’s a regression problem. If the output of your model is a class, it’s a classification problem. If the output of your model is a set of input groups, it’s a clustering problem.
Find the available algorithms. Now that you have categorized the problem, you can identify the algorithms that are applicable and practical to implement using the tools at your disposal.
Implement all of them. Set up a machine learning pipeline that compares the performance of each algorithm on the dataset using a set of carefully selected evaluation criteria. The best one is automatically selected. You can either do this once or have a service running that does this in intervals when new data is added.
Optimize hyperparameters (optional). Using cross-validation, you can tune each algorithm to optimize performance, if time permits it. If not, manually selected hyperparameters will work well enough for the most part.
Which algorithm can be used when?
Now Some description of a few algorithms. I would briefly describe them at some point in time in another blog where they would be given examples of each algorithm & will be more in-depth.
But for now, we will see which algorithm can be used when.
Linear regression and Linear classifier. Despite an apparent simplicity, they are very useful on a huge amount of features where better algorithms suffer from overfitting.
Logistic regression is the simplest non-linear classifier with a linear combination of parameters and nonlinear function (sigmoid) for binary classification.
Decision trees are often similar to people’s decision process and is easy to interpret. But they are most often used in compositions such as Random Forest or Gradient boosting.
K-means is more primal, but a very easy to understand the algorithm, that can be perfect as a baseline in a variety of problems.
PCA is a great choice to reduce the dimensionality of your feature space with minimum loss of information.
Neural Networks are a new era of machine learning algorithms and can be applied for many tasks, but their training needs huge computational complexity.
Finally, we have a cheat sheet from Scikit Learn documentation. They have developed a detailed answer to the question “ How to decide when to use which algorithm & on what dataset?”
Go through this link, there you will find scikit learn algorithm shortcut chart. It is an interactive chart with each node linked to the algorithm’s documentation.
If you’re interested in learning more about Machine Learning and other new technologies like Big data & Data science, then feel free to send us an email coffee@kevit.io, we’d be more than happy to show you some amazing facts and answer any questions that you have! And please do visit us at Kevit.io.
See Kevit.io In Action
Automating business processes with Kevit.io is now just a click away!
 kevit
kevit